




�Ƽ�ý�w bleepingcomputer ���գ�4 �� 15 �գ��l�����ģ�����Q OpenAI ���°l���� GPT-4.1 ϵ��ģ�ͣ���������� GPT-4o �mȻ���F�ش��w�S��������ܷ�δ�ܳ�Խ�ȸ�� Gemini ϵ�С�
IT֮�����Ո����OpenAI ��˾�l�� GPT-4.1��GPT-4.1 mini �� GPT-4.1 nano���ٷ��������ܷ֔����������@Щģ���ھ��̷�����������h�� GPT-4o �� GPT-4o mini��
������ SWE-bench Verified �ܷ��У�GPT-4o �ĵ÷֞� 21.4%��GPT-4.5 �ĵ÷֞� 26.6%���� GPT-4.1 �ĵ÷֞� 54.6%��
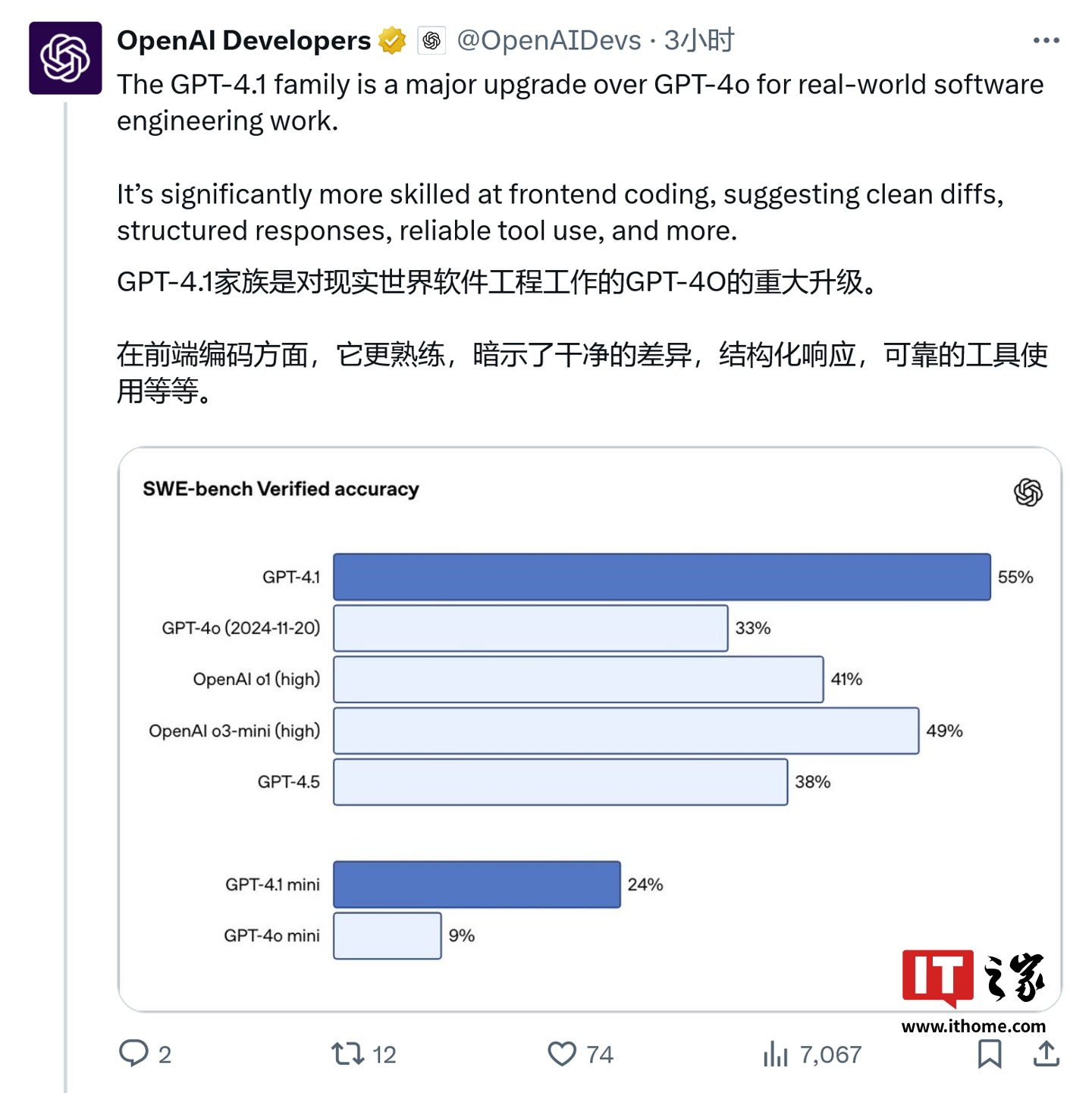
�M���������^�����������^������λ�����yԇ������^�ȸ�� Gemini ϵ�У�GPT-4.1 �����Ѕs�@¶�ӄݡ�
���� Stagehand��һ�����a���g�[���Ԅӻ���ܣ��l���Ļ��ʔ�����Gemini 2.0 Flash ���e�`�ʃH�� 6.67%�����_ƥ���ʸ��_ 90%���҃r��������ٶȸ��졣���֮�£�GPT-4.1 ���e�`�ʸ��_ 16.67%���ɱ����� Gemini 2.0 Flash �� 10 �����ϡ�
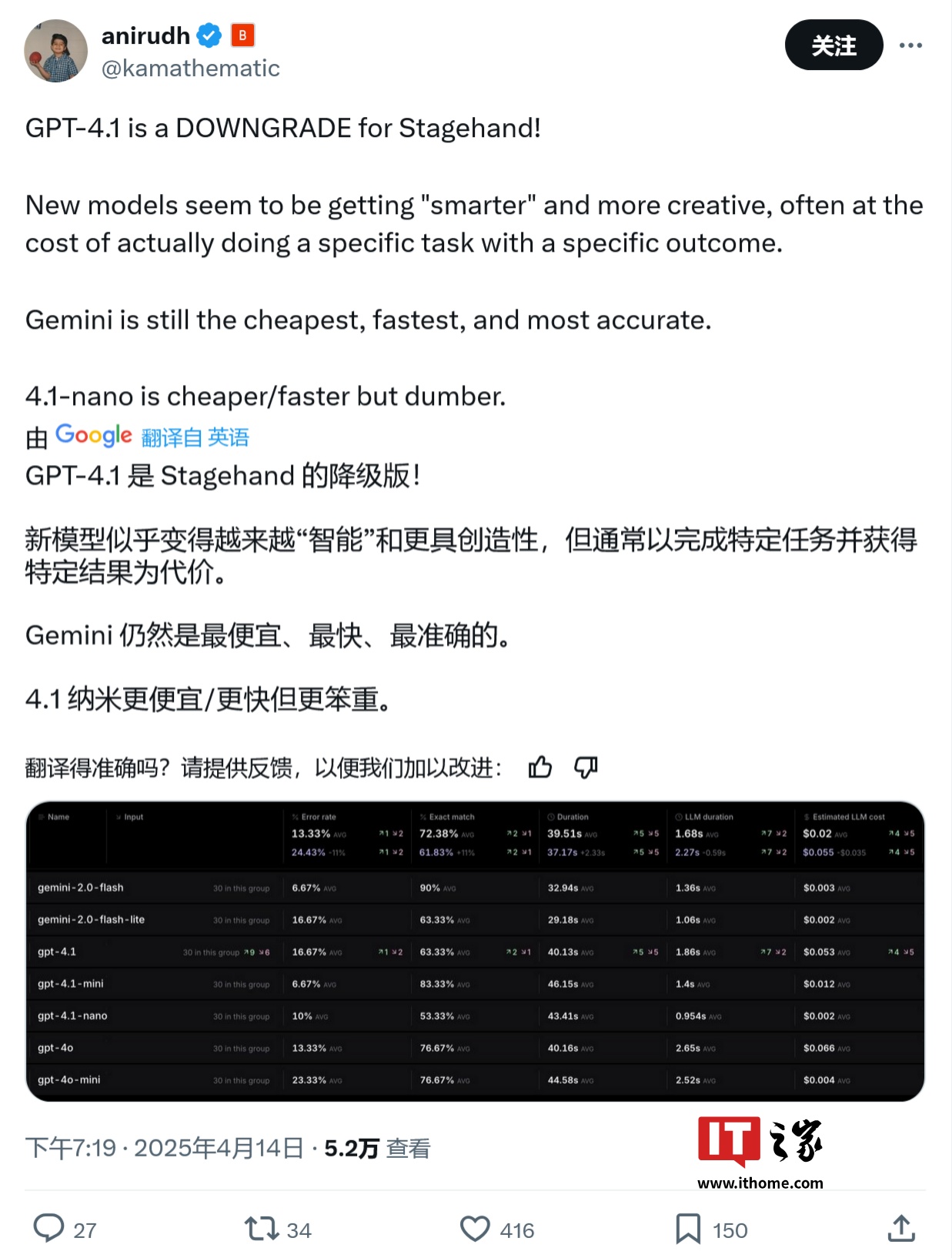
���⣬�����W RNA �ƌW�� Pierre Bongrand �ṩ�Ĕ���Ҳָ����GPT-4.1 ���ԃr�Ȳ��� Gemini 2.0 Flash��Gemini 2.5 Pro �� DeepSeek �ȸ�Ʒ��

�ھ��a��헜yԇ�У�GPT-4.1 ͬ��δ��ռ�����L��Aider Polyglot �Ĝyԇ�Y���@ʾ��GPT-4.1 �ľ��a�÷փH�� 52%���� Gemini 2.5 �t�� 73% �ijɿ��b�b�I�ȡ�
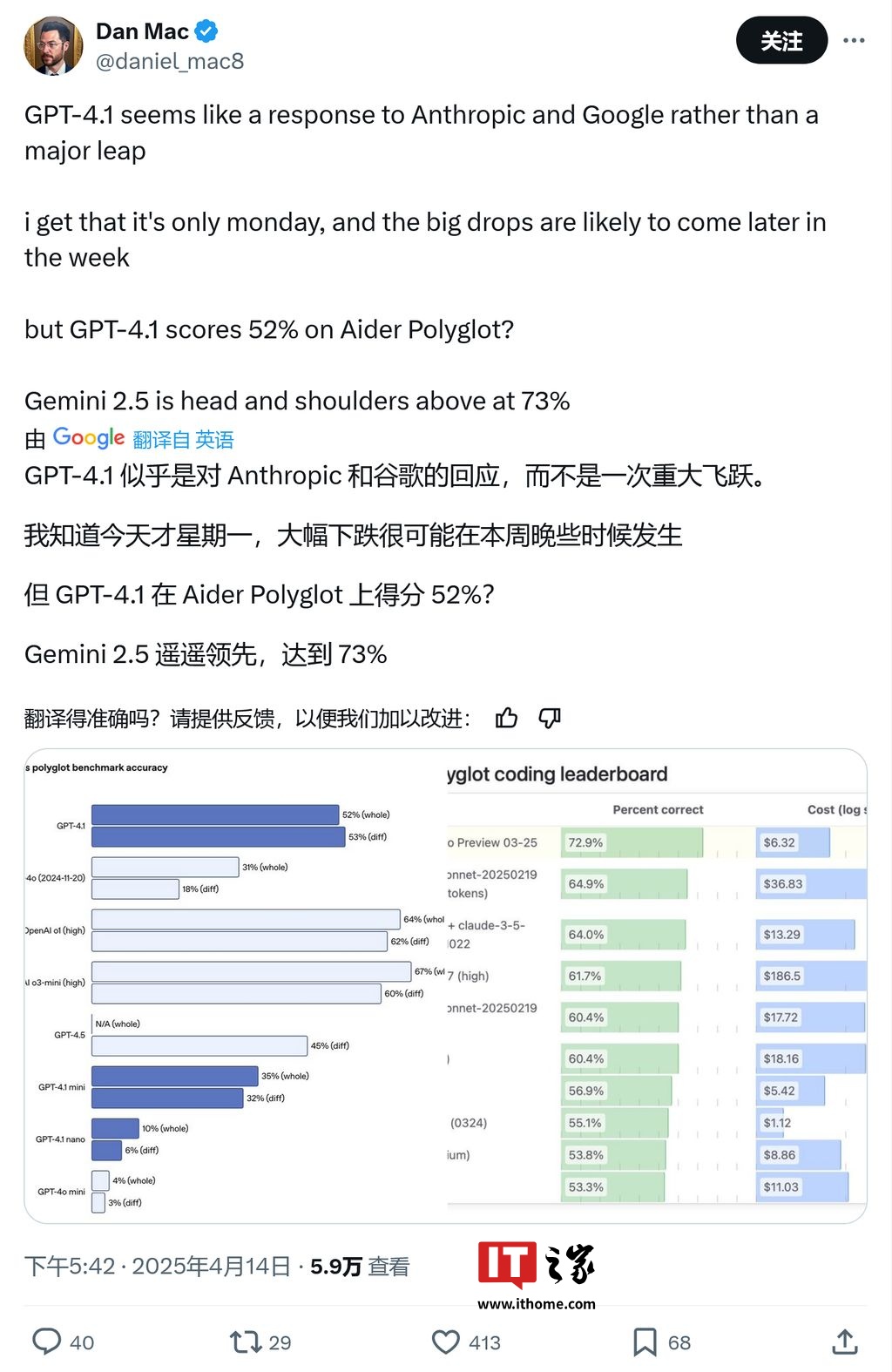
ֵ��ע����ǣ�GPT-4.1 ���w������ģ�ͣ�non-reasoning model�������侎�a�����Ԍ��ИI피⡣ 




